Student Mapping System To Measure Content Understanding | Analysis | Student Enhancement | Reduce Communication Gap

The motivating concern behind knowledge mapping research has been the desire to assess student’s understanding and utilizing a format that departs from facial recognition, standardized multiple-choice testing, evaluative feedbacks, and discourse-dependent tasks. Technologies Used in this system are Image Processing, Machine Learning, Data analysis. Modules of our project are Face detection, Facial recognition, Facial matching, Facial Expression, MCQ test, Feedback and Data analysis. For the implementation of the system, we will require a smart classroom that consists of a camera that can capture the faces of the students present in the classroom. The images will be captured after every 10 seconds of interval. After capturing the images of students, using image processing the concept of face detection will be implemented where images will be stored for further analysis. Next, the images collected during face detection will be matched with our dataset. After collecting all data our main task is facial expression matching. In facial expression matching the concept used known as Machine Learning will help us to understand emotions of students that is actual understanding of the student which can be assessed from his or her face and this can be done by the availability of the dataset which will be available with us. But these parameters are insufficient for assessing the actual student’s content understanding, so we will be adding a few more parameters that will enhance the functionality and accuracy of the system. These parameters are Multiple choice test which will be given by teachers on an external platform such as kahoot, and another parameter is Feedback where each student will provide their feedback regarding the lecture. The percentage distribution for the above parameters are , 50% for the image data, 30% for MCQ test and 20% for Feedback. Then from this result, the final data analysis will be done which provides insights for content understanding. By using this system in colleges and schools we will increase the statistic of student understanding.
Introduction
In Education, adjusting the difficulty of tasks in the class maximizes the learning effect. Students cannot learn anything from too difficult tasks, nor anything from too easy tasks. Therefore, teachers try to adjust the progress of classes. For the adjustment, they need to know the cognitive load on students. In the context, the cognitive load in learning refers to the total amount of mental activity imposed on students. In face to face classes, teaches can estimate the load, looking at their behaviors. Teachers can also ask questions to students, to receive feedback from students. Such direct communications are the best way to know the cognitive load on students, but it takes so long time to communicate with a large number of students. To avoid it, teachers assign students paper tests or e-learning tests instead of direct communication. Although these tests can check the understanding level of many students at one time, teachers cannot know the behavior of students from these tests. These tests cause miss-understanding of the cognitive load. In addition, it is hard work for students and teachers to perform tests many times. It is troublesome to adjust the difficulty level of the class for students. We must find an easy way to estimate student understanding levels correctly. There are two types of memories in the human brain: working memory and long term memory. Each of the memories has its own functions. We focus on the difference between these functions to estimate the understanding level.
The function of the working memory is information processing to understand situations and carry out tasks. Its capacity is limited and the memory is lost within about 20 s. On the other hand, the long term memory has a large size, to store patterns that are often used in the processing in the working memory. Each of the patterns is treated as one chunk when it is restored from the long term memory to the working memory. The patterns are referred to as schemata. To solve tasks which are not mastered well, students need to process information without schema. It is hard for students because the working memory should store a lot of information at the same time. Since the capacity of the working memory is small, the tasks make the cognitive load high. By contrast, when students master the tasks through repeated practices, they restore the schemata corresponding to them from the long term memory to the working memory. Since schemata combine several pieces of information into one chunk, they help students reduce the number of pieces on the working memory. Consequently, schemata reduce cognitive load. When students make mistakes and show hesitation in learning tasks, they seem not to have established schemata on the knowledge to achieve the tasks. They seem to have a high cognitive load caused by a lot of information on the working memory. Based on the idea we have introduced the Student Mapping System to measure content understanding.

LITERATURE SURVEY
Topic- Facial Emotion Recognition [1]
The interest in emotional computing has been increasing as many applications were in demand by multiple markets. This paper mainly focuses on different learning methods and has implemented several methods: Support Vector Machine (SVM) and Deep Boltzmann Machine (DBM) for facial emotion recognition. The training and testing data sets of facial emotion prediction are from FERA 2015, and geometric features and appearance features are combined together. Different prediction systems are developed and the prediction results are compared. This paper aims to design a suitable system for facial emotion recognition.
Topic- Automatic Emotion Detection Model from Facial Expression [2]
The human face plays a prodigious role for automatic recognition of emotion in the field of identification of human emotion and the interaction between human and computer for some real application like driver state surveillance, personalized learning, health monitoring etc. Most reported facial emotion recognition systems, however, are not fully considered subject-independent dynamic features, so they are not robust enough for real life recognition tasks with subject (human face) variation, head movement and illumination change. In this article, we have tried to design an automated framework for emotion detection using facial expression. For human-computer interaction facial expression makes a platform for non-verbal communication. The emotions are effectively changeable happenings that are evoked as a result of impelling force. So in real life application, detection of emotion is very challenging task. Facial expression recognition system requires to overcome the human face having multiple variability such as color, orientation, expression, posture and texture so on. In our framework we have taken frame from live streaming and processed it using Gabor feature extraction and neural network. To detect the emotion facial attributes extraction by principal component analysis is used and a clusterization of different facial expression with respective emotions. Finally to determine facial expressions separately, the processed feature vector is channeled through the already learned pattern classifiers.
Topic- Pattern Recognition and Image Processing [3]
Extensive research and development have taken place over the last 20 years in the areas of pattern recognition and image processing. Areas to which these disciplines have been applied include business (e.g., character recognition), medicine (diagnosis, abnormality detection), automation (robot vision), military intelligence, communications (data compression, speech recognition), and many others. This paper presents a very brief survey of recent developments in basic pattern recognition and image processing techniques.
Topic- Image Super-Resolution Via Sparse Representation [5]
This paper presents a new approach to single-image super resolution, based upon sparse signal representation. Research on image statistics suggests that image patches can be well-represented as a sparse linear combination of elements from an appropriately chosen over-complete dictionary. Inspired by this observation, we seek a sparse representation for each patch of the low-resolution input, and then use the coefficients of this representation to generate the high-resolution output. Theoretical results from compressed sensing suggest that under mild conditions, the sparse representation can be correctly recovered from the downsampled signals. By jointly training two dictionaries for the low- and high-resolution image patches, we can enforce the similarity of sparse representations between the low-resolution and high-resolution image patch pair with respect to their own dictionaries. Therefore, the sparse representation of a low-resolution image patch can be applied with the high-resolution image patch dictionary to generate a high-resolution image patch. The learned dictionary pair is a more compact representation of the patch pairs, compared to previous approaches, which simply sample a large amount of image patch pairs [1], reducing the computational cost substantially. The effectiveness of such a sparsity prior is demonstrated for both general image super-resolution (SR) and the special case of face hallucination. In both cases, our algorithm generates high-resolution images that are competitive or even superior in quality to images produced by other similar SR methods. In addition, the local sparse modeling of our approach is naturally robust to noise, and therefore the proposed algorithm can handle SR with noisy inputs in a more unified framework. Index.
Topic- Improving Image Quality in poor Visibility Conditions using a Physical Model for
Contrast Degredation [6]
In daylight viewing conditions, image contrast is often significantly degraded by atmospheric aerosols such as haze and fog. This paper introduces a method for reducing this degradation in situations in which the scene geometry is known. Contrast is lost because light is scattered toward the sensor by the aerosol particles and because the light reflected by the terrain is attenuated by the aerosol. This degradation is approximately characterized by a simple, physically based model with three parameters. The method involves two steps: first, an inverse problem is solved in order to recover the three model parameters; then, for each pixel, the relative contributions of scattered and reflected flux are estimated. The estimated scatter contribution is simply subtracted from the pixel value and the remainder is scaled to compensate for aerosol attenuation. This paper describes the image processing algorithm and presents an analysis of the signal-to-noise ratio (SNR) in the resulting enhanced image. This analysis shows that the SNR decreases exponentially with range. A temporal filter structure is proposed to solve this problem. Results are presented for two image sequences taken from an airborne camera in hazy conditions and one sequence in clear conditions. A satisfactory agreement between the model and the experimental data is shown for the haze conditions. A significant improvement in image quality is demonstrated when using the contrast enhancement algorithm in conjuction with a temporal filter.
Topic- A Deep Learning Approach To Universal Image Manipulation Detection Using A
New Convolutional Layer [7]
When creating a forgery, a forger can modify an image using many different image editing operations. Since a forensic examiner just test for each of these, significant interest has arisen in the development of universal forensic algorithms capable of detecting many different image editing operations and manipulations. In this paper, we propose a universal forensic approach to performing manipulation detection using deep learning. Specifically, we propose a new convolutional network architecture capable of automatically learning manipulation detection features directly from training data. In their current form, convolutional neural networks will learn features that capture an image’s content as opposed to manipulation detection features. To overcome this issue, we develop a new form of convolutional layer that is specially designed to suppress an image’s content and adaptively learn manipulation detection features. Through a series of experiments, we demonstrate that our proposed approach can automatically learn how to detect multiple image manipulations without relying on pre-selected features or any preprocessing. The results of these experiments show that our proposed approach can automatically detect several different manipulations with an average accuracy of 99:10%.
Project Scope:
· Student Mapping System To Measure Content Understanding
· Reduces the communication gap between the student and the teacher.
· Analyses the understanding of the student using facial recognition, MCQ Test, Evaluative Feedback, and Discourse dependent task.
· Improves Academics.
· Improves Students grasping power by the change in teaching method if any.
Goal
To design products that satisfy their target users, a deeper understanding is needed of their user characteristics and product properties in development related to unexpected problems users face. These user characteristics encompass the cognitive aspect, personality, demographics, and user behavior. The product properties represent operational transparency, interaction density, product importance, frequency of use, and so on. This study focuses on how user characteristics and product properties can influence whether soft usability problems occur, and if so, which types. The study will lead to an interaction model that provides an overview of the interaction between user characteristics, product properties, and soft usability problems.
Method and results
In total three surveys and one experiment were conducted. The first survey was a questionnaire survey to explore what usability problems users experienced in the Netherlands and South Korea. This study resulted in the categorization of soft usability problems. Based on the findings from the studies, and interaction model (PIP model: Product-Interaction-Persona model) was developed which provides insight into the interaction between user characteristics, product properties, and soft usability problems. Based on this PIP model a workshop and an interactive tool were developed. Companies can use the PIP model to gain insights into probable usability problems of a product they are developing and the characteristics of those who would have problems using the product.
Validation
The PIP model was validated in the companies involved in the project to see how it is used in the product development process and what should be improved. The validation also included workshops in which designers in the companies could experience and learn how the findings and the model and the tool are applicable to their design process.
Design and Implementation constraints
While Developing a project, the requirement for a System environment is mandatory, i.e the constant environment is the requirement to fulfill the actual product development. If any changes occur in the system environment, it might affect the product features.
Functional Requirements
· System must be fast and efficient
· User-friendly GUI
· Reusability
· Performance
· System Validation input
· Smart Classroom
SYSTEM DESIGN -
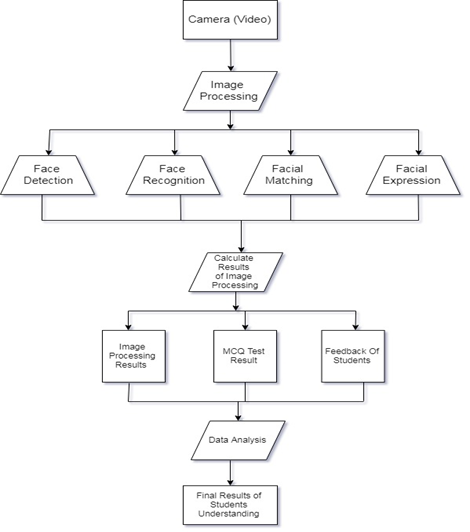
Advantages
· Covers the Students Study Focus
· Teachers can plan for changes in Method of Teaching if required
· It will help in decreasing the communication Gap between Teachers and Students
Limitations
· Continuous Internet connectivity
· Start and Stop Sessions may Extend due to Teachers careless behavior
IMPLEMENTATION
KNN Algorithm
K-nearest neighbors (KNN) algorithm is a type of supervised ML algorithm that can be used for both classifications as well as regression predictive problems. However, it is mainly used for classification predictive problems in the industry.
A specialized training phase and uses all the data for training while classification.
Non-parametric learning algorithm − KNN is also a non-parametric learning algorithm because it doesn’t assume anything about the underlying data.
K-nearest neighbors (KNN) algorithm uses ‘feature similarity’ to predict the values of new datapoints which further means that the new data point will be assigned a value based on how closely it matches the points in the training set. We can understand its working with the help of following steps −
Step 1 − For implementing any algorithm, we need a dataset. So during the first step of KNN, we must load the training as well as test data.
Step 2 − Next, we need to choose the value of K i.e. the nearest data points. K can be any integer.
Step 3 − For each point in the test data do the following −
• 3.1 − Calculate the distance between test data and each row of training data with the help of any of the method namely: Euclidean, Manhattan or Hamming distance. The most commonly used method to calculate distance is Euclidean.
• 3.2 − Now, based on the distance value, sort them in ascending order.
• 3.3 − Next, it will choose the top K rows from the sorted array.
• 3.4 − Now, it will assign a class to the test point based on the most frequent class of these rows.
Step 4 − End
Example
The following is an example to understand the concept of K and working of KNN algorithm −
Suppose we have a dataset which can be plotted as follows −
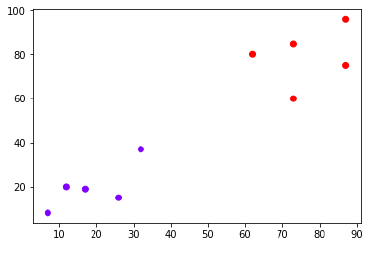
Now, we need to classify new data point with black dot (at point 60,60) into blue or red class. We are assuming K = 3 i.e. it would find three nearest data points. It is shown in the next diagram −
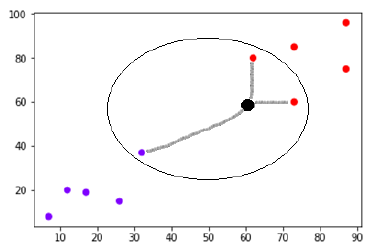
We can see in the above diagram the three nearest neighbors of the data point with the black dot. Among those three, two of them lie in Red class hence the black dot will also be assigned in red class.
Face Detection
Convolutional Neural Network Model (CNN)
Based on the image resolution, it will see h x w x d( h = Height, w = Width, d = Dimension ). Eg., An image of 6 x 6 x 3 array of the matrix of RGB (3 refers to RGB values) and an image of 4 x 4 x 1 array of the matrix of the grayscale image.
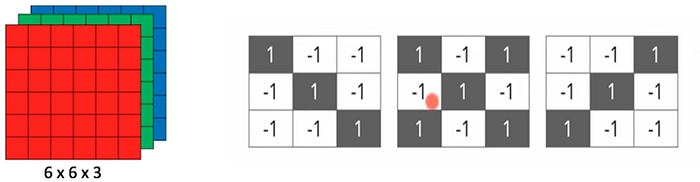
Convolutional neural network (CNN) is one of the main categories to perform image Detection, Image recognition, image classifications. Objects detections, recognition faces, etc., are some of the areas where CNNs are widely used.
CONCLUSION
This system can contribute to estimating students’ understanding level. In this method, we analyze the understanding of students in the classroom. The analysis reveals students understanding level from their facial images, MCQ Test, and Student Feedback. First, the images which are captured will be calculated, added to that the results to MCQ and Feedback will be calculated and a final probability will be provided. We also capture their faces while they attempt the MCQ test to analyze their behavior. Consequently, this method promotes students’ understanding.
REFERENCES
[1] Ma Xiaoxi, Lin Weise and Huang Dongyan, Dong Minghui, Haizhou Li, “Facial Emotion Recognition” 2017 IEEE 2nd International Conference on Signal and Image Processing
[2] Debishree Dagar, Abir Hudait, H.K. Tripathy, M.N. Das, “Automatic Emotion Detection Model from Facial Expression”, 2016 International Conference on Advanced Communication Control and Computing Technologies (ICACCCT)
[3] Jiequan Li and M. Oussalah, “Automatic Face Emotion Recognition”, School of Engineering, Department of Electronic, Electrical and computer Engineering, University ofBirmingham.
[4] King-Sun Fu and Azriel Rosenfeld “Pattern Recognition and Image Processing”, IEEE Transaction on computers, Vol. C-25, №12, December 1976
[5] Jianchao Yang, John Write, Thomas S. Huang and Yi Ma, “Image Super-Resolution Via Sparse Representation” IEEE Transaction on Image Processing, Vol. 19, №11, November 2010
[6] John P. Oakley and Brenda L. Satherley “Improving Image Quality in poor Visibility Conditions using a Physical Model for Contrast Degredation”, IEEE Transactions on Image Processing, Vol. 7, №2, February 1998
[7] Belhassen Bayar, Matthew C. Stamm “A Deep Learning Approach To Universal Image
Manipulation Detection Using A New Convolutional Layer” IH&MMSec 2016, June 20–23, 2016, Vigo, Spain c 2016 ACM. ISBN 978–1–4503–4290–2/16/06
[8] Rahul Chauhan, Kamal Kumar Ghanshala, R.C Joshi “Convolutional Neural Network (CNN) For Image Detection and Recognition” 978–1–5386–6373–8/18/$31.00 ©2018 IEEE
[9] A.Rishika Reddy, P. Suresh Kumar “Predictive Big Data Analytics in Healthcare” 2016 Second International Conference on Computational Intelligence & Communication Technology.
[10] M.D. Anto Praveena, Dr. B. Bharathi, “A Survey Paper on Big Data Analytics” INTERNATIONAL CONFERENCE ON INFORMATION, COMMUNICATION & EMBEDDED SYSTEMS (ICICES 2017)
Project By-
Thinksprout Infotech
Contact : info@thinksproutinfotech.com
+91 9028470100
+91 9969824528
